
Los índices en MySQL permiten localizar y devolver registros de una forma sencilla y rápida. Son especialmente útiles cuando queremos buscar elementos de entre los millones y hasta billones de registros que puede contener una tabla en un momento dado. Cuando no usamos índices, a veces podemos percibir que MySQL tarda demasiado en responder una consulta o, incluso para usuarios inexpertos, puede parecer que se ha creado un índice pero que no se siente una mejora en la velocidad. De todo eso vamos a tratar en este artículo.

Para muchos desarrolladores, el manejo de índices es un asunto poco menos que esotérico. Algunas veces funciona bien, otras el sistema se degrada en rendimiento con el tiempo y el incremento de datos, pero todo tiene una explicación. En este sentido, debemos saber que una elección inteligente suele mejorar significativamente la velocidad de consulta a nuestra base de datos; pero lo primero es comprender qué nos permite hacer un índice:
Qué son los índices en bases de datos
Imagina que tiene toda la información telefónica de los habitantes de un país como Venezuela, de una población aproximada de 30 millones de habitantes. Suponga también que los datos no están ordenados.
Nota: Para que los índices se noten realmente, debemos contar con un número significativo de registros en una tabla. Pero no es necesario que sean millones. Creando una buena estrategia de índices podemos mejorar sensiblemente la velocidad de las consultas en tablas con varios miles de registros. Claro está que la mejora suele ser proporcional y depende mucho de esa cantidad de registros. También un uso inadecuado de ellos puede redundar en pérdida de rendimiento, por lo que conviene saber qué es lo que estamos haciendo.
Veamos una consulta como esta:
SELECT * FROM personas WHERE apellido="zamora"
Sin ningún orden en nuestros datos, MySQL debe leer todos los registros de la tabla "personas" y efectuar una comparación entre el campo "apellido" y la cadena de caracteres "zamora" para encontrar alguna coincidencia (en la vida real habrá muchas coincidencias). A medida que esta base de datos sufra modificaciones, como un incremento en el numero de registros, dicha consulta irá requiriendo un mayor el esfuerzo de la CPU y el uso de memoria necesaria para ejecutarse.
Si tuviéramos una guía telefónica a mano localizaríamos fácilmente a cualquiera con apellido "zamora" yendo al final de la guía, a la letra "Z". El método en sí está dado en función a como están ordenados los datos y en el conocimiento de los mismos. En otras palabras, localizamos rápidamente a "zamora" porque está ordenado por apellido y porque conocemos el abecedario.
Si abrimos un libro técnico observamos que posee un índice al final del libro, contenido por términos o conceptos importantes con su correspondiente numero de página. Si sabemos de qué trata el libro buscamos la palabra que nos interesa y encontramos la expresión junto con su número de página.
Los índices de base de datos son muy similares. Al igual que el escritor decide crear un índice de términos y conceptos importantes de su libro, como administradores de una base de datos decidimos crear un índice respecto a una columna.
Nota: A lo largo de la documentación variada que encontrarás sobre MySQL en Internet en general, se utilizan términos como INDICE o CLAVE para referirse a lo mismo. Por tanto, decir por ejemplo "apellido es una clave de la tabla personas" es igual a decir que el "campo apellido de la tabla personas está indexado".
Creando índices en MySQL
Usando el ejemplo inicial, para que la consulta anterior se ejecutase más rápido en nuestro sistema gestor de base de datos, nos vendría bien crear un índice por apellido. Para crear ese índice podemos utilizar una sentencia en lenguaje SQL como la siguiente:
ALTER TABLE personas ADD INDEX (apellido)
De esta forma sencilla indicamos a MySQL que genere una lista ordenada de todos los apellidos de la tabla personas, así como en el ejemplo del libro tenemos los números de teléfono ordenados por el apellido.
Nota: Te animamos a usar los comandos de MySQL directamente para experimentar con éstas u otras consultas en lenguaje SQL. Si lo prefieres, puedes usar algunas aplicaciones para administrar una base de datos, ya sean en entorno web como PhpMyAdmin o en aplicaciones de escritorio como Heidi SQL.
Viendo los índices desde la perspectiva del servidor de base de datos
Los índices se almacenan de forma que la base de datos (o motor) pueda eliminar registros o filas determinadas del resultado de una consulta ejecutada, son dinámicos y su gestión es transparente para el usuario o desarrollador.
Tenemos que saber que, sin ninguna Indexación, MySQL (así como cualquier otro gestor de base de datos) lee cada registro, consumiendo tiempo, utilizando muchas operaciones de ENTRADA/SALIDA en el disco e incluso llegando a corromper el sistema de caché del servidor.
Un aspecto muy importante es que ¡no es recomendable crear un índice por cada columna de una tabla! MySQL necesita tener una lista separada de los valores de índice y actualizarlos conforme van cambiando. Al final, el manejo de índices requiere un equilibrio adecuado entre espacio de almacenamiento y tiempo.
Una tabla con un campo indexado de MySQL usa más espacio y un BIT extra (por lo menos hasta la versión 5) para las consultas.
Para experimentar puedes usar una tabla disponible en el siguiente link
Dicha tabla posee más de 300.000 nombres de personas (sin teléfonos) y no se encuentra indexada.
Puedes subirla con los siguientes pasos desde PhpMyAdmin: selecciona la base de datos -> Importar -> Archivo a importar:
Selecciona el archivo descargado -> Continuar
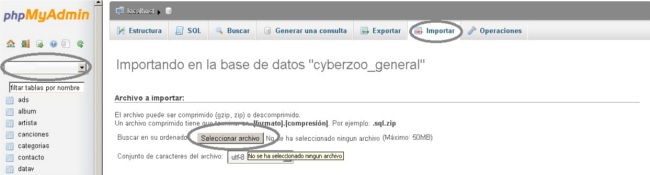
Debes seleccionar la base de datos luego la opción SQL
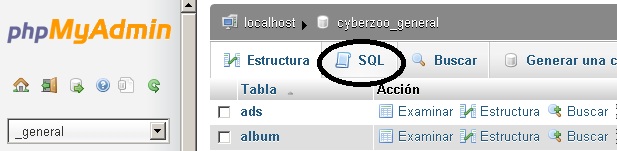
Entonces podrás ejecutar consultas de prueba sobre esa tabla y luego crear el índice con la misma opción usando:
ALTER TABLE personas ADD INDEX (apellido)
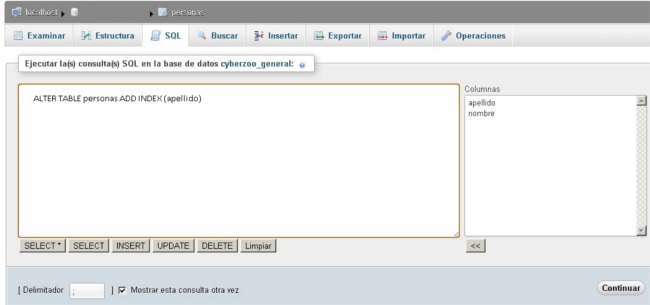
Una vez creado el índice, puedes volver ejecutar las mismas consultas y comparar los tiempos de respuesta.
En algunos entornos bien optimizados en MySQL, no serán tan significativas las diferencias de tiempo, porque las consultas ya estarán cacheadas no dejando apreciar la diferencia. En el momento de escribir este artículo, en un servidor de pruebas (no es una estadística ni una prueba de performance profesional) observé un cambio significativo de casi 100 milisegundos entre una consulta de esta tabla no indexada y otra consulta después de haber aplicado un índice.
Nota: Además, por mi experiencia, algunas veces me ha tocado optimizar una página web creada por otras personas y recuerdo especialmente un caso en el que la página tardaba en cargar de manera extraordinariamente extraña. Existían páginas cuya carga ralentizaba el sitio hasta en 20 o 30 segundos más que otras páginas, lo que era demasiado. Después de hacer un análisis benchmark desde PHP nos dimos cuenta de que ciertas consultas a MySQL eran las que estaban perjudicando el proceso de carga y se solucionó simplemente creando unos índices en las tablas en aquellos campos que se mencionaban en la parte del "Where" del SQL. A menudo, los desarrolladores no nos damos cuenta de que la optimización de las consultas es uno de los puntos más importantes para la rapidez de carga de un sitio.
En próximos artículos detallaremos los diferentes tipos de índices, así como los diferentes tipos de tablas que ofrece este popular motor de base de datos MySQL que te ayudarán a incrementar el funcionamiento óptimo de tus sistemas o servidores web con MySQL sin tener que aumentar los costos de hardware.
Fuente: enlace





No hay comentarios:
Publicar un comentario